为什么AI 时代测试复兴?
因为代码可以被轻松生产出来,没有测试验收的代码很容易变成 AI Slop。
没有测试保证的代码持续迭代从出生开始就悬着达摩克利斯之剑,后面越迭代心里就越没底。这一点连续几个月使用 AI 维护同一套代码的人应该才能体会到。
AI 时代我最推崇端到端测试。 本质上面向业务的 AI Coding 也是一个拟合需求的大型强化学习场景。
端到端测试优先
回归测试的本质,我们写测试是因为正确的测试确实可以提高开发效率,所以选择怎样写测试的判断标准之一就是要找到 ROI(Return Of Investment) 最高的截面。柳胜认为测试的ROI计算公式为1

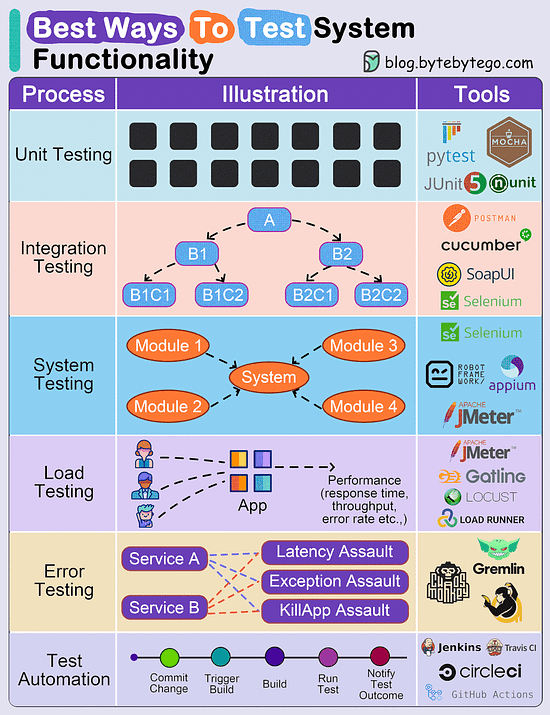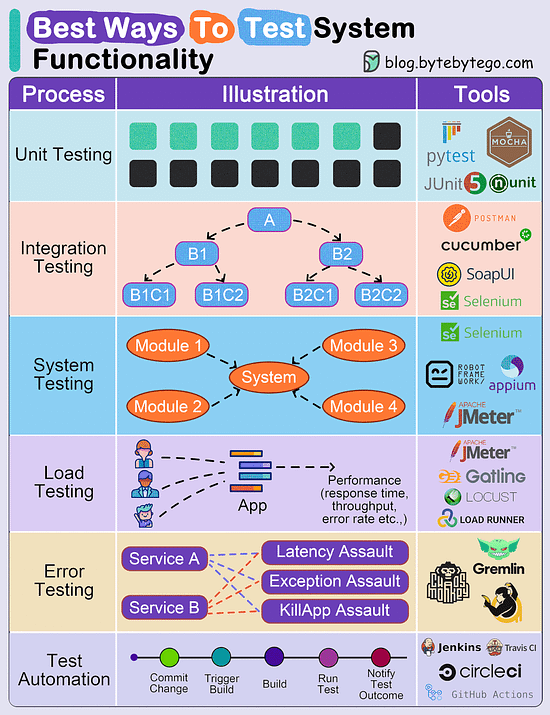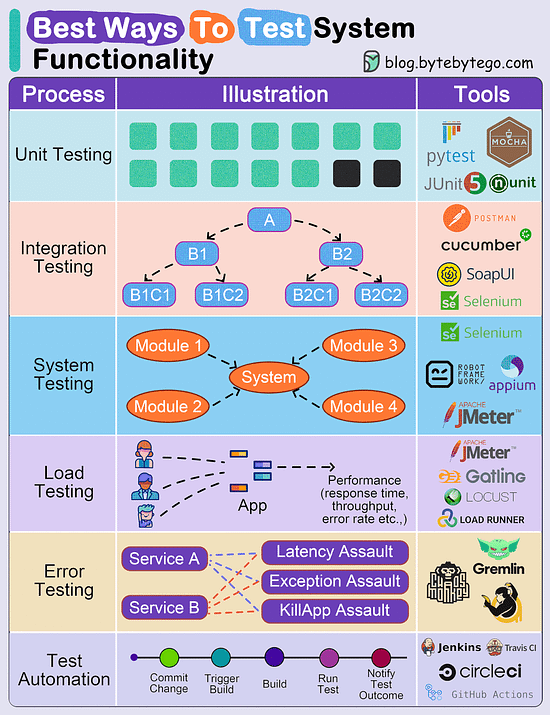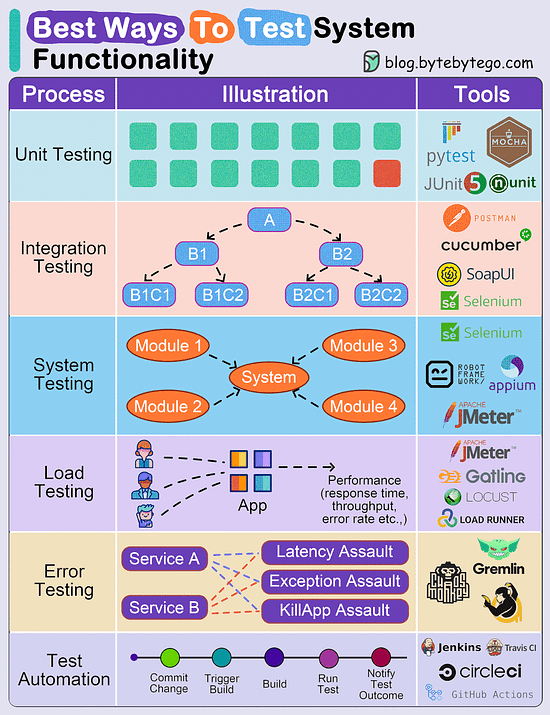
在测试金字塔模型下,越往底部,测试的 ROI 越高。
- UI 测试 关注功能场景测试、易用性测试和可执行性测试
- 接口测试 关注不同数据的流动、接口的性能和错误恢复能力
- 单元测试 关注算法的正确性和性能
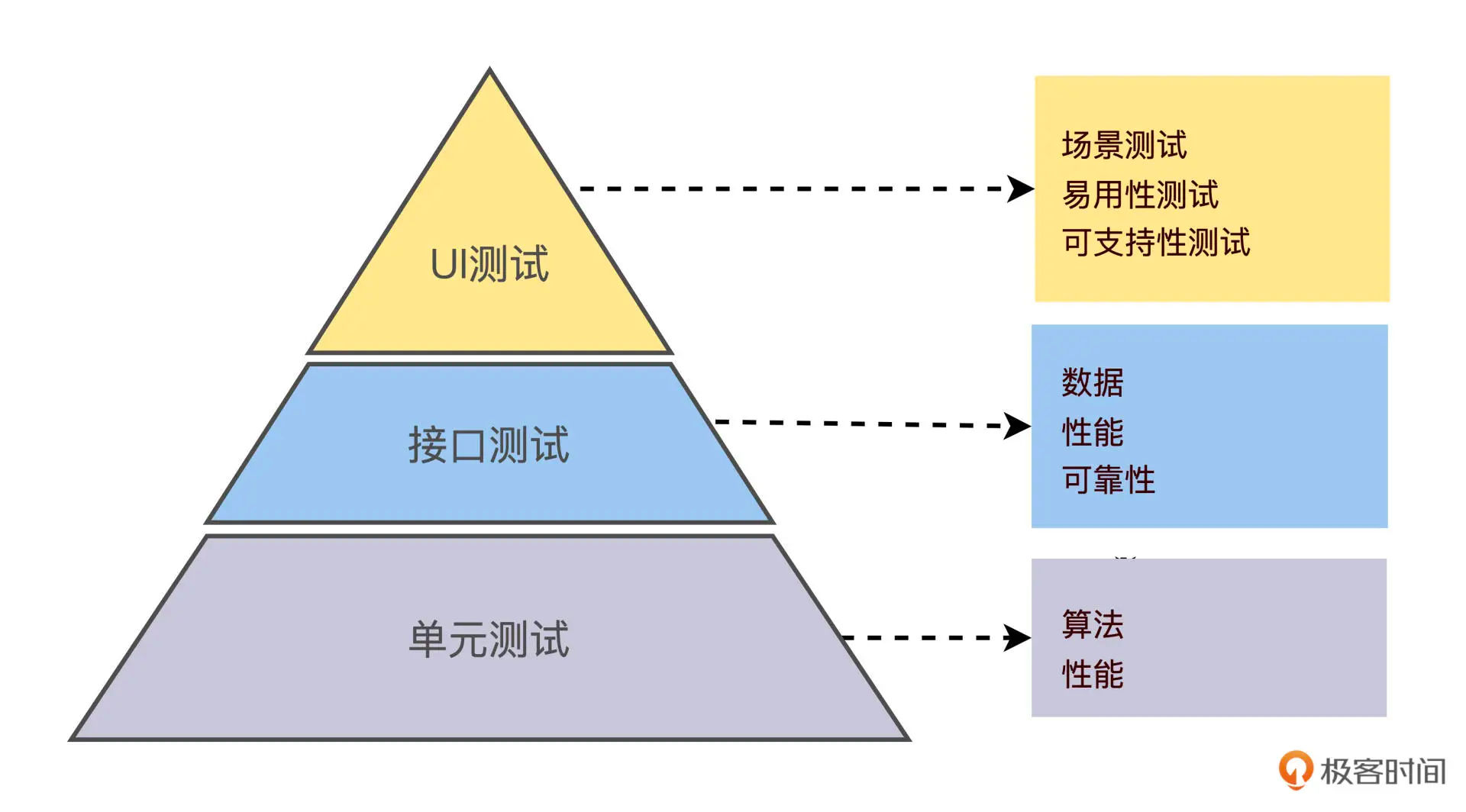
上图中的 UI 测试通常也被称为 端到端测试,对外的接口测试对后端通常也就是 集成测试。
而单元测试是什么呢?是针对一个类或者某个方法的测试吗?不是,徐昊指出单元测试(Unit Test)是一个具有误导性的提法,在TDD中不应该有这样的说法,应代之以单元级别功能测试(Unit Level Functional Test)。2
其本质是能提供快速反馈的低成本的研发测试3。一般认为在测试金字塔模型下,越往底部,测试的ROI越高,是因为越往下手工运行时间是越短的,运行次数是越多的;而越往上开发测试和维护测试的成本都越高。
LLM 出现之前,集成测试通常ROI不如单元测试,并且和单元测试测试内容有较多重合,所以两者使用需要追求平衡,柳胜提出
1. 在单元测试阶段验证尽可能多的业务逻辑,这样能让集成测试关注在外部依赖上。 2. 在依赖可控的情况下,集成测试应走尽可能多的真实的外部依赖服务。
可控的依赖比如数据库,就应该尽可能真实地去交互;不可控的如第三方接口,应该尽可能用定好的逻辑来Mock接口。
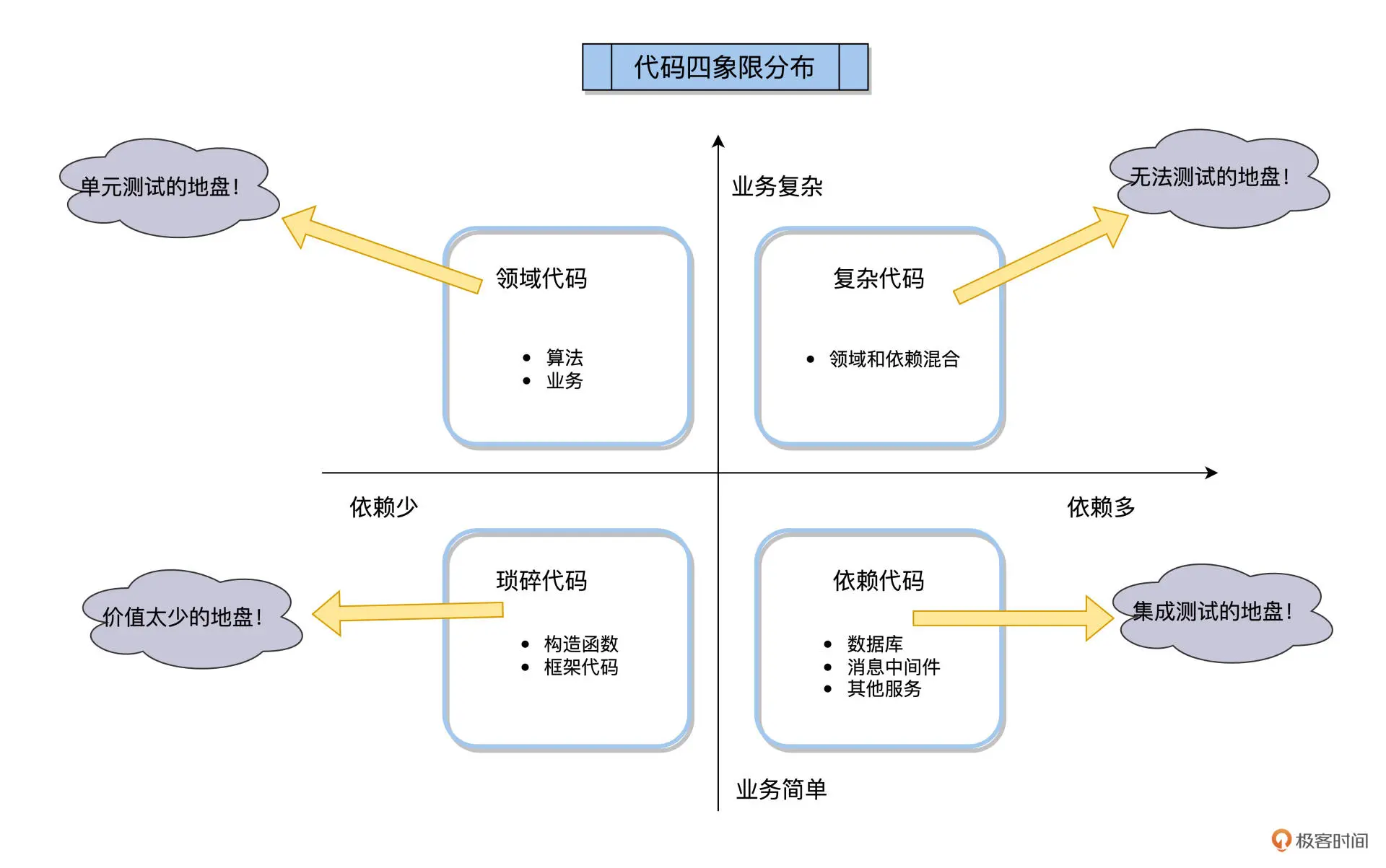
但是在 AI 时代,测试的生产和维护成本都越来越低。 我们甚至可以为本地环境 mock 出各个中间件和 DB 的接口来模拟线上环境。
为了更贴近生产交付的需要,我们在原有单元测试的基础上,可以更多考虑将整个应用拉起来测试的端到端测试。
什么是端到端测试?
众说纷纭的测试概念
不过我们做的测试叫什么都不重要,能够起到测试的功能才是最重要的。不过这里我依然想对端到端测试下一个定义。
定义
这里采用柳胜的说法4
集成测试是处在单元测试和端到端测试中间的一个状态。如果所有的外部服务都 Mock 了,集成测试就变成了单元测试,往另外一个方向,如果所有的外部服务都是真实的,集成测试又变成了端到端的测试。
如果让我下一个定义,端到端测试就是被测对象中,包括被测对象本身在内的所有依赖都是生产环境需要的测试。
关于测试比较先进也比较激进的是 TDD——测试驱动开发,强调应该先写测试再写实现。
TDD 与测试用例的诞生
TDD 大体分为两派:
伦敦学派
- 预先设计
- 按照调用栈层层实现
- 按调用栈从外而内的写测试
芝加哥学派
- 不假设任何实现
- 演进式重构
- 按功能写测试然后再从内重构
一开始就胸有成竹、有能力顶层设计好的就按伦敦学派来,不然就按芝加哥学派来一步步重构得到更好的代码。
红绿循环(Red-Green-Refactor Cycle)
无论是伦敦学派还是芝加哥学派,TDD 的核心实践方法论都是 红绿循环,这是一个反复迭代的过程:
🔴 Red(红):写一个失败的测试
先写一个描述期望行为的测试,这个测试必然会失败,因为对应的实现代码还不存在。这一步的目的是:
- 明确需要实现什么功能
- 定义 API 的接口契约
- 确保测试是可运行且有意义的
🟢 Green(绿):写最少的代码使测试通过
写最小化的实现代码,使得上一步的测试通过。这里的关键是”最少”——不要过度设计,不要添加不必要的功能。目标只有一个:让测试绿起来。
🔵 Refactor(蓝/重构):改进代码质量
在测试保持绿色的前提下,重构代码以改进:
- 可读性和可维护性
- 性能和效率
- 代码结构和设计
- 消除重复代码
这个阶段有测试作为保障网,可以放心地修改代码而不用担心破坏功能。
循环迭代
然后回到第一步,为下一个功能或场景重复这个循环。每个循环通常很小(几分钟到十几分钟),形成一个快速的反馈回路:
测试失败 → 写代码 → 测试通过 → 重构 → 测试失败(新需求) → ...
这个循环带来的核心价值是:
- 快速反馈:每个小改动都能立即验证
- 设计逐步演进:通过不断的重构,代码设计逐步改善
- 全面覆盖:因为先写测试,最后的代码覆盖率天然很高
- 信心充足:任何时刻都知道代码是否还能工作
一个很常见的场景: foo() 处理业务数据之前有一些校验逻辑
- 伦敦学派会设计好一个 validator 的接口,再专注于实现这个 validator
- 芝加哥学派则会先选择直接在 foo() 中实现校验的功能,然后再重构出一个 validator 接口
测试用例和代码的映射
一个实际的 TDD Java 测试案例,按照接口-条件-测试 case 的不同层层划分用例。
Junit 5 的@Nested 可以允许以静态内部成员类的形式对测试用例类进行逻辑分组。
下面是一个测试Stack功能的例子:
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertThrows;
import static org.junit.jupiter.api.Assertions.assertTrue;
import java.util.EmptyStackException;
import java.util.Stack;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Nested;
import org.junit.jupiter.api.Test;
@DisplayName("A stack")
class TestingAStackDemo {
Stack<Object> stack;
@Test
@DisplayName("is instantiated with new Stack()")
void isInstantiatedWithNew() {
new Stack<>();
}
@Nested
@DisplayName("when new")
class WhenNew {
@BeforeEach
void createNewStack() {
stack = new Stack<>();
}
@Test
@DisplayName("is empty")
void isEmpty() {
assertTrue(stack.isEmpty());
}
@Test
@DisplayName("throws EmptyStackException when popped")
void throwsExceptionWhenPopped() {
assertThrows(EmptyStackException.class, stack::pop);
}
@Test
@DisplayName("throws EmptyStackException when peeked")
void throwsExceptionWhenPeeked() {
assertThrows(EmptyStackException.class, stack::peek);
}
@Nested
@DisplayName("after pushing an element")
class AfterPushing {
String anElement = "an element";
@BeforeEach
void pushAnElement() {
stack.push(anElement);
}
@Test
@DisplayName("it is no longer empty")
void isNotEmpty() {
assertFalse(stack.isEmpty());
}
@Test
@DisplayName("returns the element when popped and is empty")
void returnElementWhenPopped() {
assertEquals(anElement, stack.pop());
assertTrue(stack.isEmpty());
}
@Test
@DisplayName("returns the element when peeked but remains not empty")
void returnElementWhenPeeked() {
assertEquals(anElement, stack.peek());
assertFalse(stack.isEmpty());
}
}
}
}基于用户故事的前端测试
对于一个完整的项目,我们应该从用户故事出发,通俗来说,模拟用户动线—用户进入页面会看什么、点击什么、触发什么接口,以此来扩展用例。
我们可以尝试 GWT 法则:
- Given:情景/条件
- When:采取什么行动
- Then:得到什么结果
AI 时代,我们不需要写具体的测试代码,更多是用 GWT 法则表达清楚用例让 AI 能懂即可。传统的复杂的测试断言需要也不需要,我们是让 AI 学会像人一样验证问题、排查问题。
实践中,TDD 我也没能很好遵循,因为很多时候来不及,更想着先实现就好。或者我自己也没想清楚要实现什么样,先做再说。不过我很清楚认识到,这个本质上是因为我对需求想的不够清楚,属于战略懒惰。
前端的页面怎么测试呢?推荐 Chrome DevTools Plugin,Google 浏览器官方出品,可以自动点击浏览器页面、截图甚至看 DevTools 中的日志!
/plugin marketplace add ChromeDevTools/chrome-devtools-mcp
/plugin install chrome-devtools-mcp@chromedevtools-chrome-devtools-mcp基于OpenAPI 的接口测试
对于后端接口来说,OpenAPI 是描述接口的核心契约具象化文件。这个文件在 AI 测试的时候不应该被改变。需要给 AI 明确测试的目标和边界。在 OpenAPI 的基础上,我们需要维护一个包含以下环节的最佳实践作为模型学习如何对当前环境做端到端测试:
- 用例设计
- 应用热部署与重启
- 日志查询
- 接口测试
- 用例验证
当然也可以将这个作为当前仓库的 skill 维护:
/project/.claude/skills/e2e-test-skill/ralph-loop
Claude Code 本身是 Loop 组成的智能体,并且内部自带 Loop。
而人类在使用 Claude Code 的过程中,提需求-规划-实现-review-再提需求…本身也是一个 Loop,这也是 Human-In-The-Loop 的泛化版。自然地,借助 Stop Hook,我们可以强制 CC 每次在其自然停下的时候都让其反思任务是否已经完成,如果没完成就必须继续 Loop:
/ralph-loop "Fix xxx" --max-iterations 10 --completion-promise "FIXED"这个命令表示让模型修复 xxx,一直到 CC 认为自己修复完成显式输出 “FIXED” 才会停止,最大迭代 10 次。 这个 Loop 可以用于更大的层面,比如挨个实现需求: https://snarktank.github.io/ralph/
安装 ralph-loop 使用 /plugin 命令:
/plugin marketplace add anthropics/claude-code
/plugin install ralph-wiggum@anthropics-claude-code再套一个 Agent Loop?
ralph-loop 很不错,但缺点也很明显——单纯让 CC 自己反思,并不能给 CC 指导性的意见,并不能真的像我们自己一样 review CC 每次停下来的输出,或者当 CC 问你要 A 还是 B 方案的时候,给 CC 一个方案。
解决办法就是在最外面的 Loop 里面再加一个 Agent,这个 Agent——Supervisor 将真正扮演我们自己的角色。它会 Fork 完整的会话上下文,评估实际的工作质量,而不是简单检测一些关键词或信号。
Supervisor 等于你来推进项目
- Agent 是否在等待用户确认?
- 是否做了应该自己做的事?
- 代码质量是否达标?
- 用户需求是否全部满足?
当然这个比较大的问题就是我们的决策权也一并交给 CC 了。当 CC 给出选项 A、B、C 的时候,我们的分身或许能根据当下情况选好 A、B、C,但目前应该还是不能真的像人一样提出 D 的选项给 CC。
Ralph 与 Supervisor 的比较
| 方面 | Ralph | CCC(Supervisor) |
|---|---|---|
| 检测方式 | AI 输出结构化状态 + 规则解析 | Supervisor AI 直接审查 |
| 评估方式 | 基于信号和规则 | Fork 会话上下文评估实际质量 |
| 灵活性 | 需要更新规则代码 | 更新 Prompt 即可 |
结论: 不过复杂场景,AI 归根结底不能代替人做判断。这是人的核心竞争力所在。
基于测试的无参数 AI 应用级别“学习”
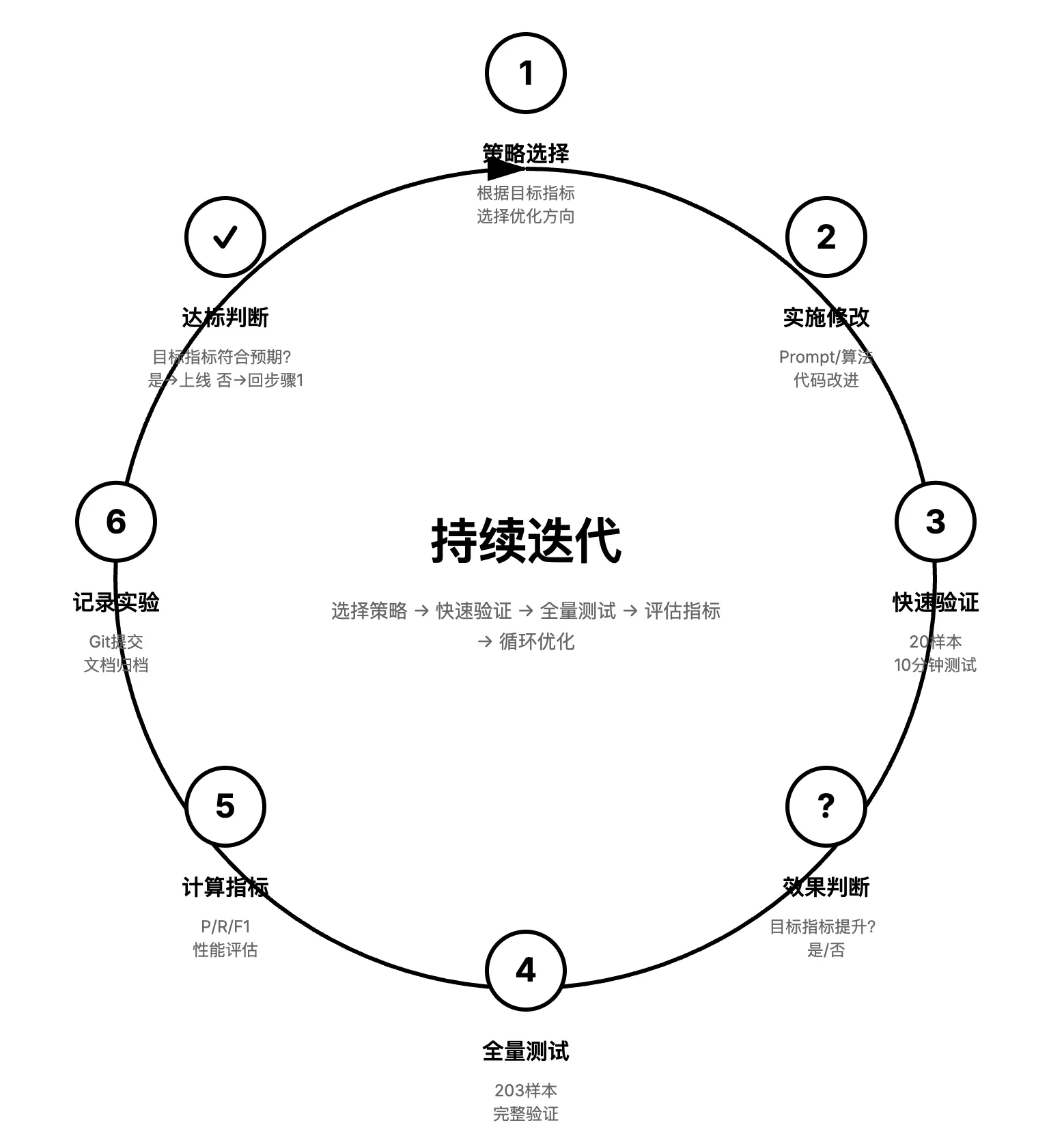
-
使用 ralph-loop 持续自迭代,目前全召回率 0 → 43% ,没有人类手工参与

-
实践证明,只要系统本身没有运行是错误,CC 可以持续运行 6 小时以上

-
甚至会产生 强化学习时 Aha Moment 的感觉(不过整体启发式策略和实验反馈还得做的更好)
