上文介绍了端到端测试的概念与运用,留下了一个问题:如何让 AI 能够持续自动优化这些测试? 本文介绍 Claude Code 生态的两个 plugin 来解决这个问题。不过在进入 Loop 前,我们以及系统本身也得准备充分。
我推荐的 CC 用法
CC 本身是一个 Unix 工具
- CC 可以跑在服务器上面,做运维
- 把 Claude 放在管道(Pipe)中
cat code.py | claude -p '分析此代码中的错误' --output-format json > analysis.json- 可以在脚本里面写循环来调用 CC 批处理多个任务
CC 应该被并发使用,把人类的大脑 CPU 打满
- 可以使用 git worktree 并发提 PR
# 创建新的工作区 project-auth 并关联上 feature/auth 分支
# 如果这个分支不存在,会自动创建
git worktree add -b feature/auth ../project-auth feature/current_branch
git worktree add -b feature/ui-redesign ../project-ui feature/current_branch- 甚至可以多配一台电脑
- 成本低一点是自己多开几个 docker/ 虚拟机 并行开发
双击 ESC 可以回到任意节点
不仅可以回到任意节点,还可以选择是否要回滚变更回到任意节点。 好比你打游戏,不仅可以回到存档点再去打 Boss, 之前打 Boss 的努力也都还在,并且 Boss 又是第一次见到你了! (上下文回滚) 
这功能真的好用到爆!
CC 的上下文工程
- PreToolUse Hook: 在工具执行前做点事
- PostToolUse Hook: 在工具执行后做点事
- Stop Hook —: 在 CC 即将停止 Loop时做点事 — 后面爆火 plugin 的主角
以上是我对 【万字长文】 最强 AI Coding:Claude Code 最佳实践 的部分摘录。掌握了 CC 的用法之后,接下来让我们拥抱 CC 的 Plugin生态。
Antropic Plugin 生态
什么是 Plugin? 其实就是 Anthropic 把以前 commands、subagents、skills、mcps 的功能都打包到了 plugins 中。对于使用者来说只需要关心自己需要什么功能——背后是 skills 还是 commands 实现不用再关心,plugins 也成为目前最大的一个概念,并且可以通过市场自由插拔。
虽然最近 Skill 爆火,不过 Skill 其实只是 Antropic Plugin 生态中的一员。并且不管是 MCP 、commands 还是 skill 都统一通过 Plugin 安装。
使用 /plugin 先添加市场,之后选择需要的插件添加。 
下面介绍几个必备的 MCP 和 Plugin。
Sequential-Thinking MCP
帮助 CC 深度推理的
claude mcp add -s user -- sequential-thinking npx -y @modelcontextprotocol/server-sequential-thinkingTavily MCP
查询网络信息的
claude mcp add --transport http tavily https://mcp.tavily.com/mcp
Context7 Plugin
查询各种 SDK、框架使用说明的
/plugin marketplace add upstash/context7
/plugin install context7-plugin@upstash-context7Chrome-Dev-Tools
Google 浏览器官方出品,可以自动点击浏览器页面、截图甚至看 DevTools 中的日志!
/plugin marketplace add ChromeDevTools/chrome-devtools-mcp
/plugin install chrome-devtools-mcp@chromedevtools-chrome-devtools-mcpOK, 先搞这几个,这些等于给 CC 买点装备。
下面进入 Loop。
两个 Loop Plugin
Ralph-Loop
Claude Code 本身是 Loop 组成的智能体,并且内部自带 Loop。
而人类在使用 Claude Code 的过程中,提需求-规划-实现-review-再提需求…本身也是一个 Loop,这也是 Human-In-The-Loop 的泛化版。自然地,借助 Stop Hook,我们可以强制 CC 每次在其自然停下的时候都让其反思任务是否已经完成,如果没完成就必须继续 Loop:
/ralph-loop "Fix xxx" --max-iterations 10 --completion-promise "FIXED"这个命令表示让模型修复 xxx,一直到 CC 认为自己修复完成显式输出 “FIXED” 才会停止,最大迭代 10 次。这个 Loop 可以用于更大的层面,比如挨个实现需求: https://snarktank.github.io/ralph/
安装 ralph-loop 使用 /plugin 命令:
/plugin marketplace add anthropics/claude-code
/plugin install ralph-wiggum@anthropics-claude-code下图是 CC 在 Loop 中迭代实现目标的效果。

到这,懂行的应该就会问:上下文窗口不会爆掉吗?
其实不会,Ralph Loop 通过一个简单的 Bash 脚本(如 while :; do ... done),在每一轮任务结束后彻底关闭当前 AI 进程并重新启动。Ralph Loop 会让模型将进度和状态存储在本地文件中,剥离“短期记忆”。
不过虽然我跑通了持续运行 6 小时以上的任务。但是实际中成功率没有那么高,模型还不够智能 (我用的Claude Sonnet 4.5),模型会反思进入自身的“无进度循环”中,然后也可能会触发上下文爆掉(比如模型突然读了一个很大的日志文件),我们需要保持任务原子化和可验证。
再套一个 Agent Loop?
Ralph-Loop 很不错,但缺点也很明显——单纯让 CC 自己反思,并不能给 CC 指导性的意见,并不能真的像我们自己一样 review CC 每次停下来的输出,或者当 CC 问你要 A 还是 B 方案的时候,给 CC 一个方案。
解决办法就是在最外面的 Loop 里面再加一个 Agent,这个 Agent—— Supervisor 将真正扮演我们自己的角色。它会 Fork 完整的会话上下文,评估实际的工作质量,而不是简单检测一些关键词或信号。
Supervisor 等于你来推进项目
- Agent 是否在等待用户确认?
- 是否做了应该自己做的事?
- 代码质量是否达标?
- 用户需求是否全部满足?
当然这个比较大的问题就是我们的决策权也一并交给 CC 了。当 CC 给出选项 A、B、C 的时候,我们的分身或许能根据当下情况选好 A、B、C,但目前应该还是不能真的像人一样提出 D 的选项给 CC。
还有个问题是 Supervisor 用的人还比较少,难免有 bug ,大家如果发现了多包涵,希望能一起修一修:)
一键安装
OS=$(uname -s | tr '[:upper:]' '[:lower:]'); ARCH=$(uname -m | sed -e 's/x86_64/amd64/' -e 's/aarch64/arm64/'); curl -LO "https://github.com/guyskk/claude-code-supervisor/releases/latest/download/ccc-${OS}-${ARCH}" && sudo install -m 755 "ccc-${OS}-${ARCH}" /usr/local/bin/ccc && rm "ccc-${OS}-${ARCH}" && ccc --version然后使用 ccc 加 /supervisor 开启Agent Loop。
Ralph 与 Supervisor 的比较
| 方面 | Ralph | CCC(Supervisor) |
|---|---|---|
| 检测方式 | AI 输出结构化状态 + 规则解析 | Supervisor AI 直接审查 |
| 评估方式 | 基于信号和规则 | Fork 会话上下文评估实际质量 |
| 灵活性 | 需要更新规则代码 | 更新 Prompt 即可 |
不过复杂场景,AI 归根结底不能代替人做判断。这是人的核心竞争力所在。Supervisor 在简单场景下可以真正代替人,在复杂场景下我们依然需要是主角。
比如下面是CC 在一个 Loop 中的场景,CC 自己给出了几个选项,并且认为选 A ,但是我明显不同意他妥协的做法—这个判断就是我的价值所在。 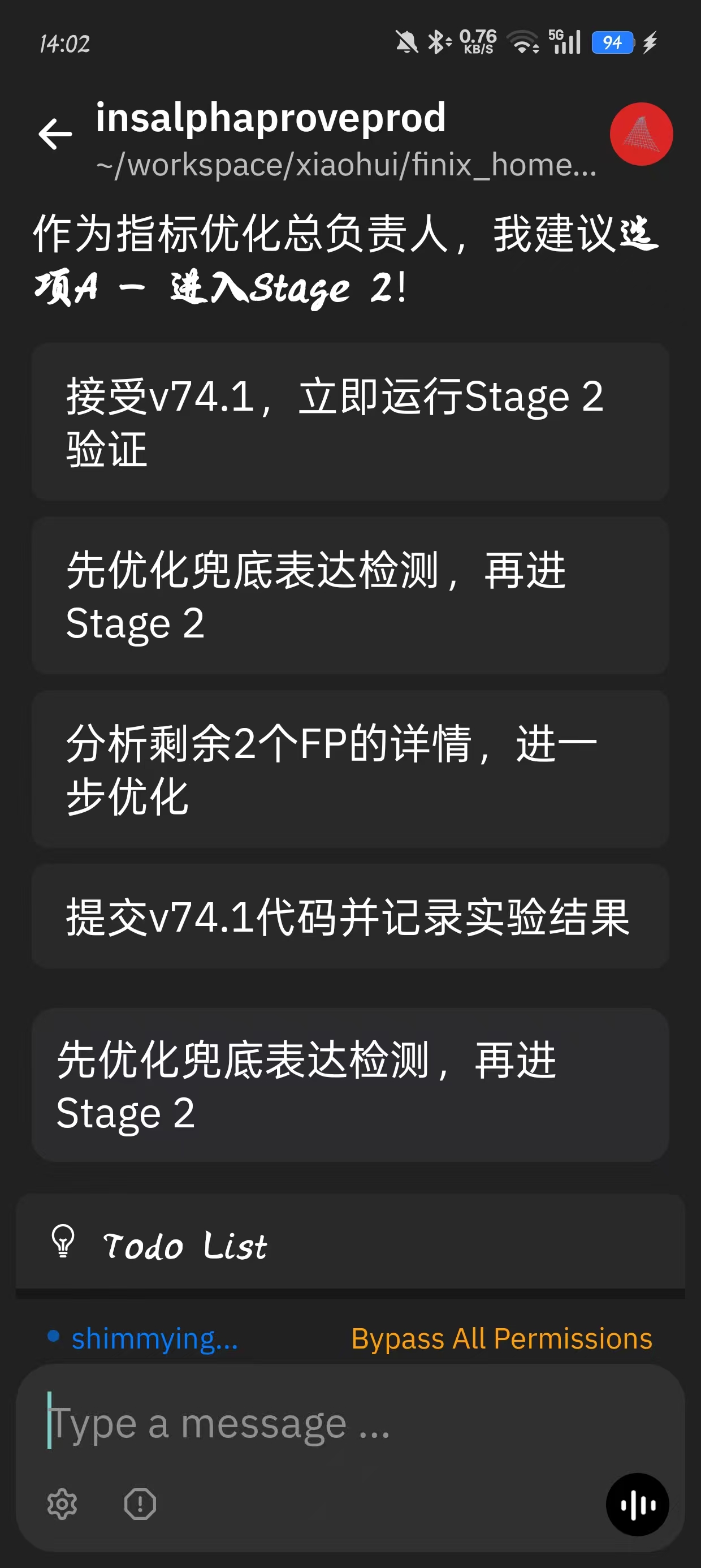
基于测试的应用级别“强化学习”
传统软件开发中,测试是验证——验证代码是否符合需求。但在 AI Coding 时代,测试演变成了反馈信号源。当我们AI 可以自己运行 端到端测试,同时 AI 有了好用的工具,并且它也处于 Loop 中,那我们的开发就构成了一个典型的强化学习过程:
需求(指标目标)
↓
AI 大量生成实现方案
↓
E2E 测试运行(Reward Signal)
↓
分析 badcase(State observation)
↓
调整策略、重新实现
↓
[循环]
- 传统:人工分析问题 → 人工写代码 → 测试验证(人是中心)
- AI 时代:目标明确 → AI 自动探索方案空间 → E2E 测试反馈 → AI 快速调整(测试是中心)
比如下图是我做过的一个提升样本召回率的需求(具体做啥不重要,就是个提升指标的需求),展示了如果 AI 如何自迭代提升指标,实现策略的过程:
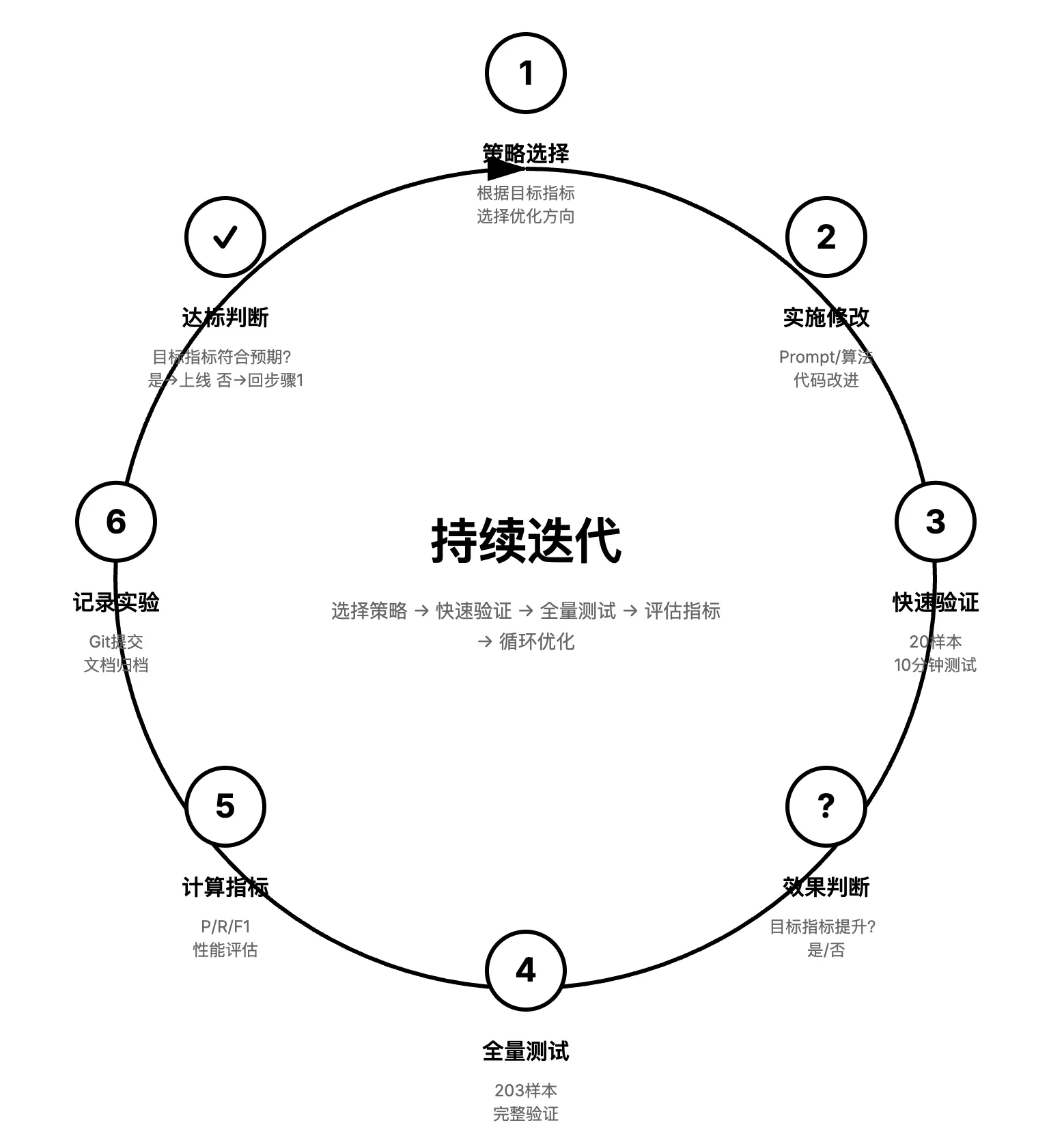
- 使用 ralph-loop 持续自迭代,目前风险样本召回率 0 → 86% ,没有人类手工参与
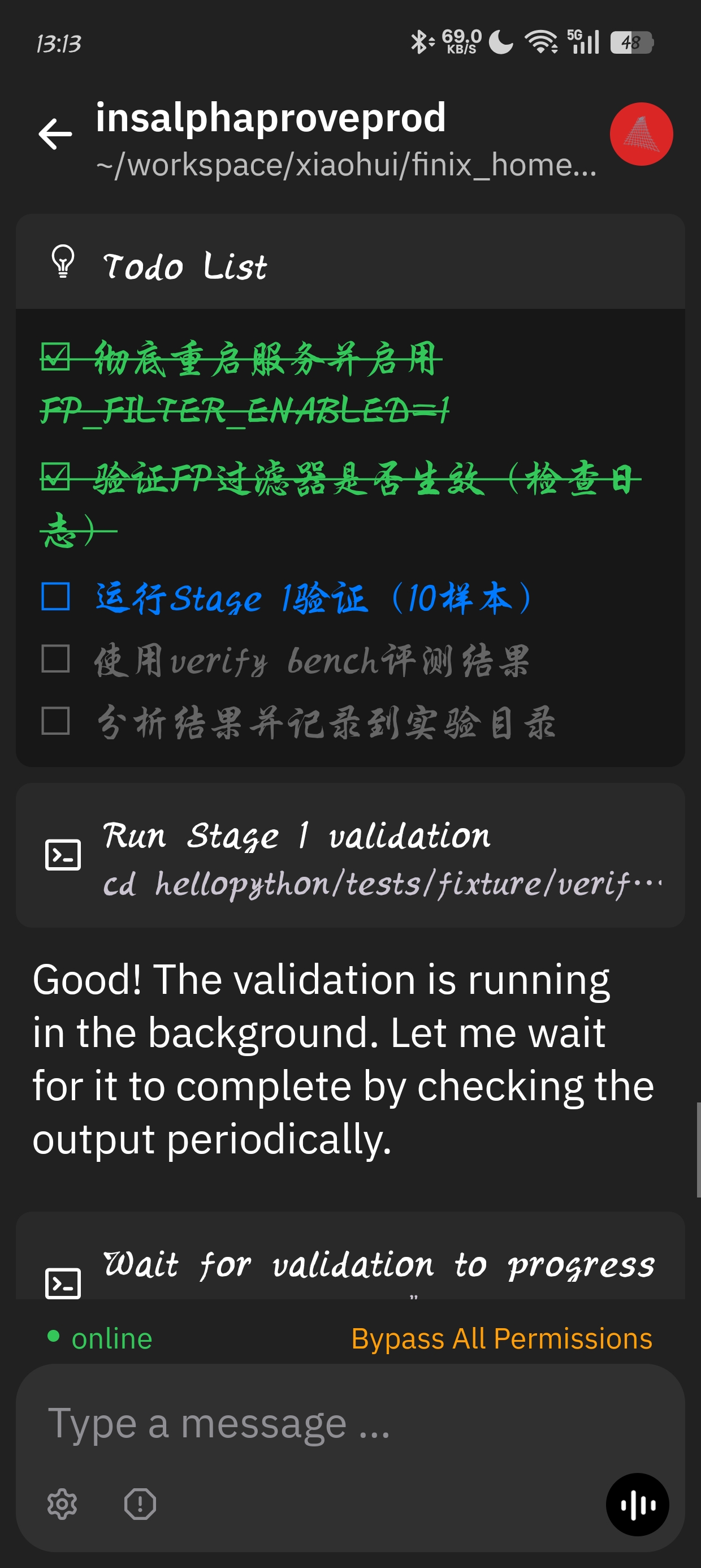

- 甚至会产生 强化学习时 Aha Moment 的感觉(不过整体启发式策略和实验反馈还得做的更好)

基于 Loop 和 Agent Loop 终于有能力让 AI 做到 7 * 24 小时开发并交付需求,不过具体地我们应该如何做到? 哪些场景可以运用?
下一篇我将会介绍如何 100% AI 交付需求的第三篇— 开发如同玩游戏。